For more details on the filter patterns learned in the source task, please visit here
: https://github.com/moses1994/singing-voice-detection/tree/master/3-filter-patterns-learned-in-source-task
For more details on the filter patterns learned in the target task, please visit here
: https://github.com/moses1994/singing-voice-detection/tree/master/3-filter-patterns-learned-in-target-task
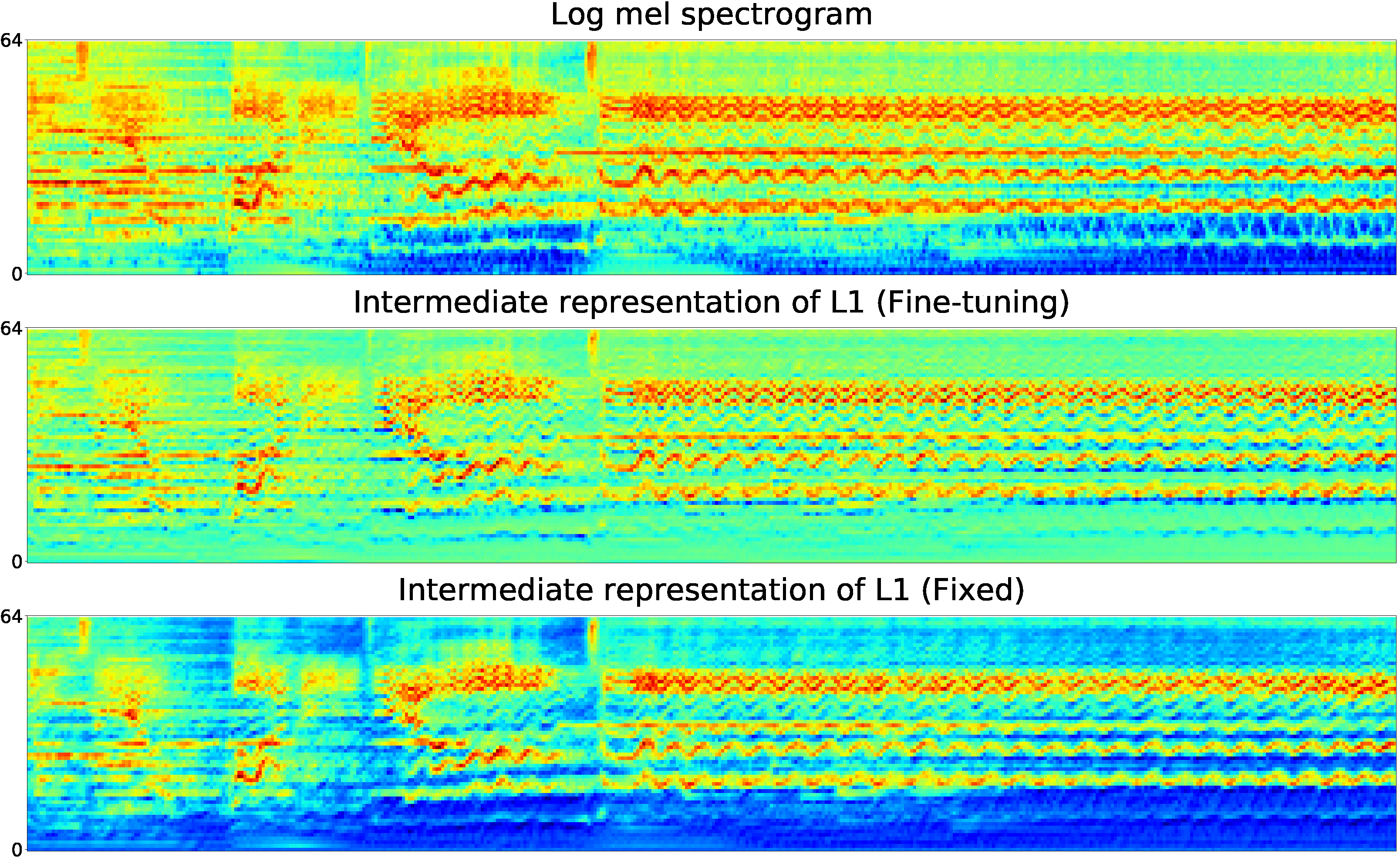
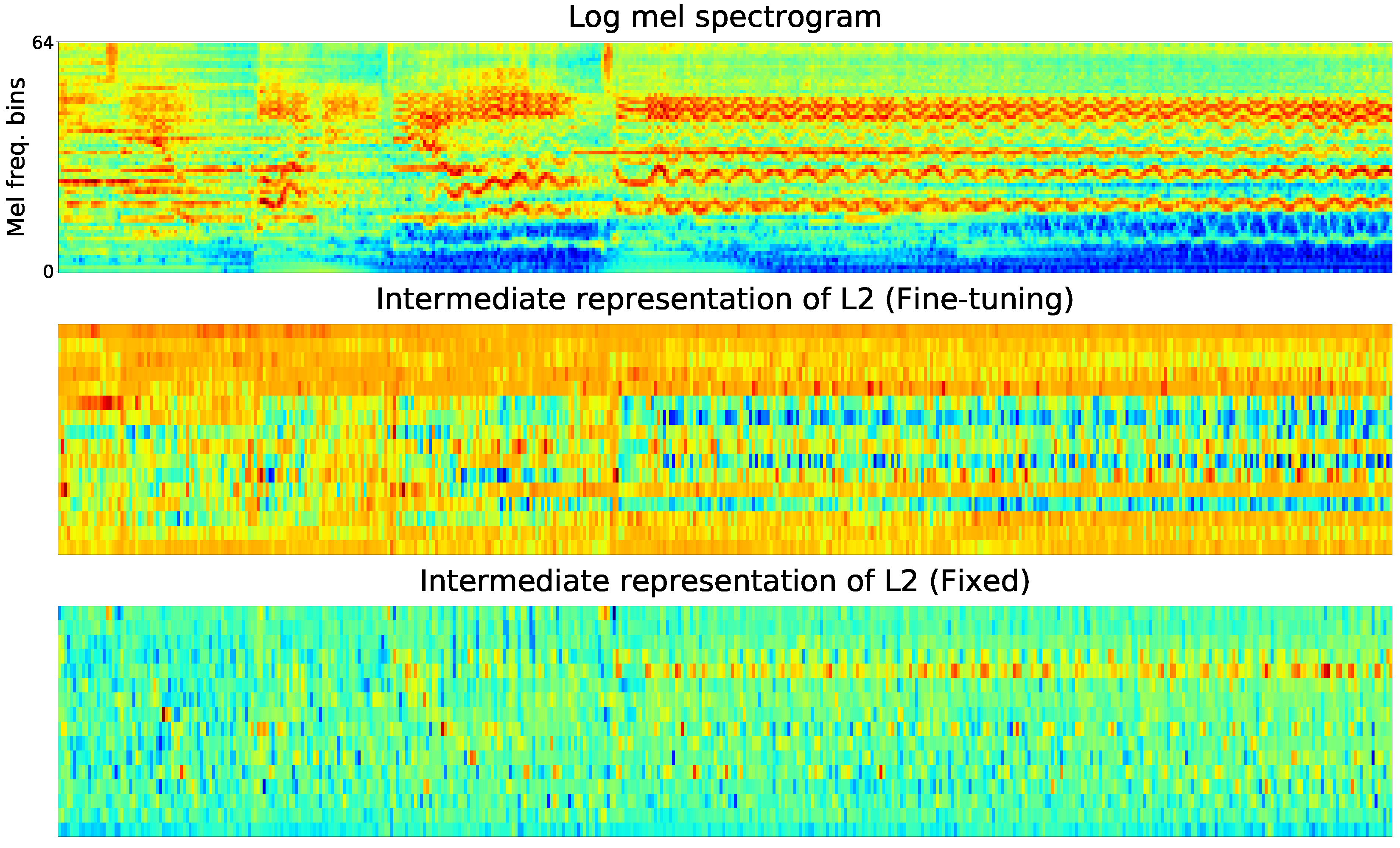
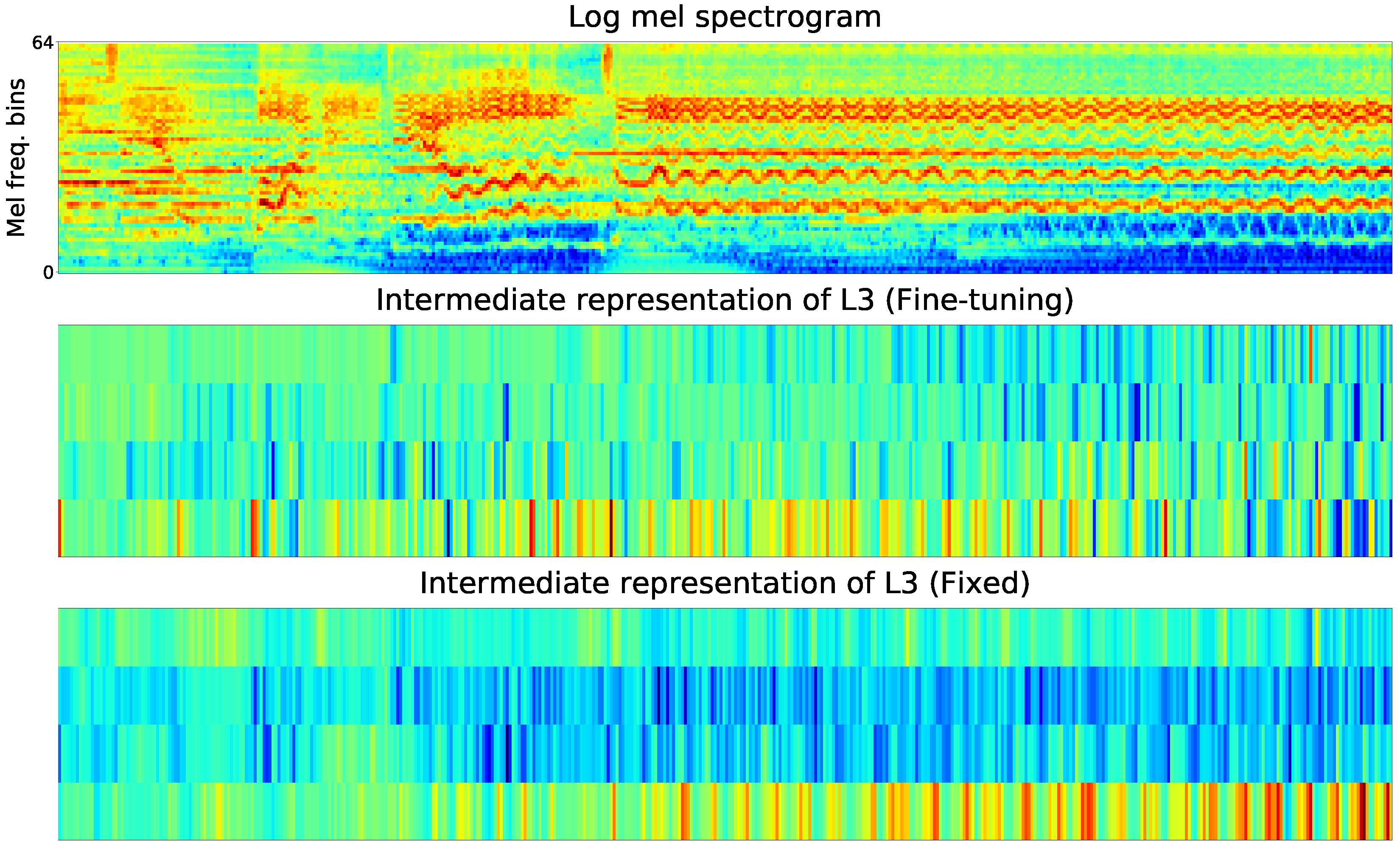
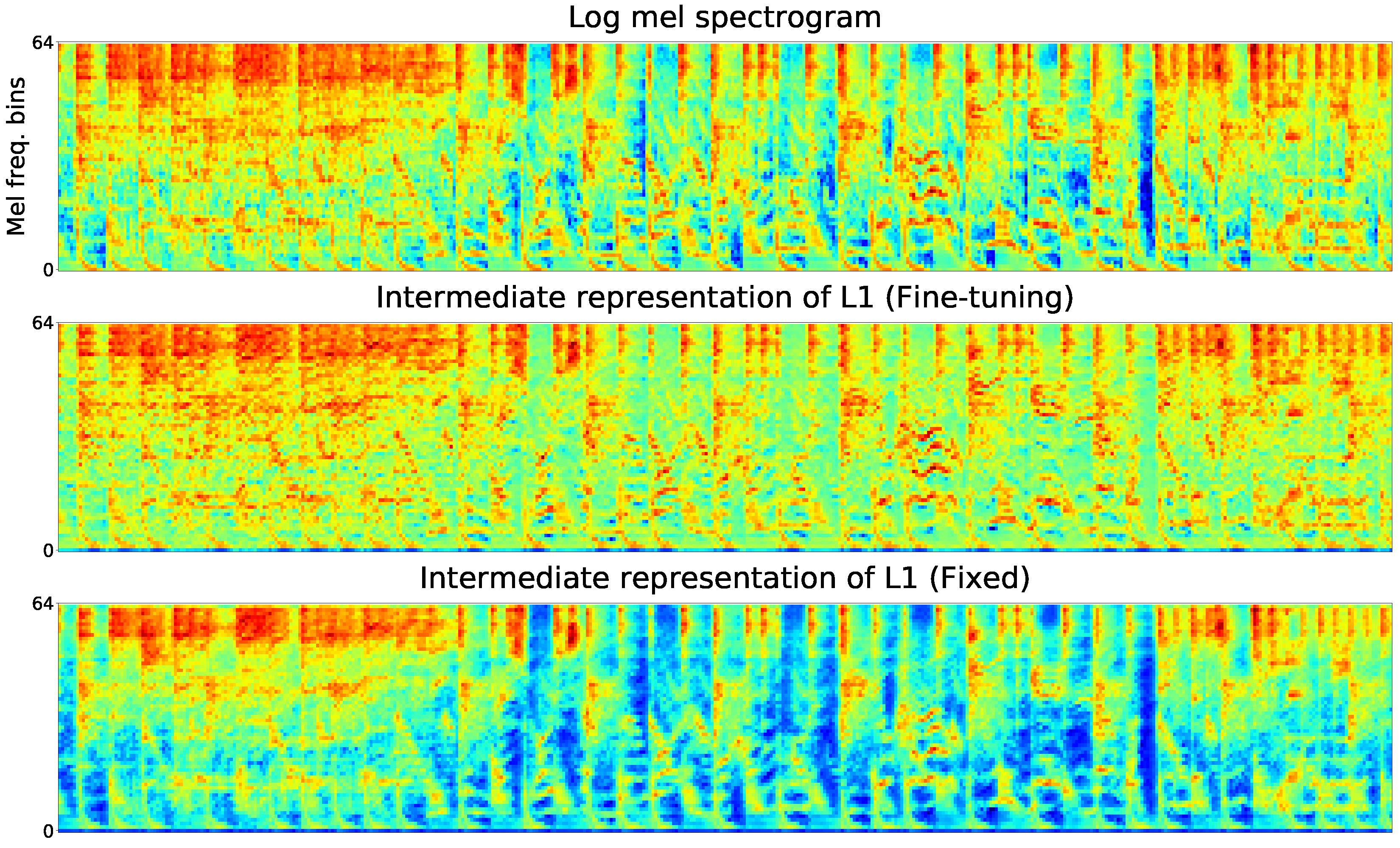
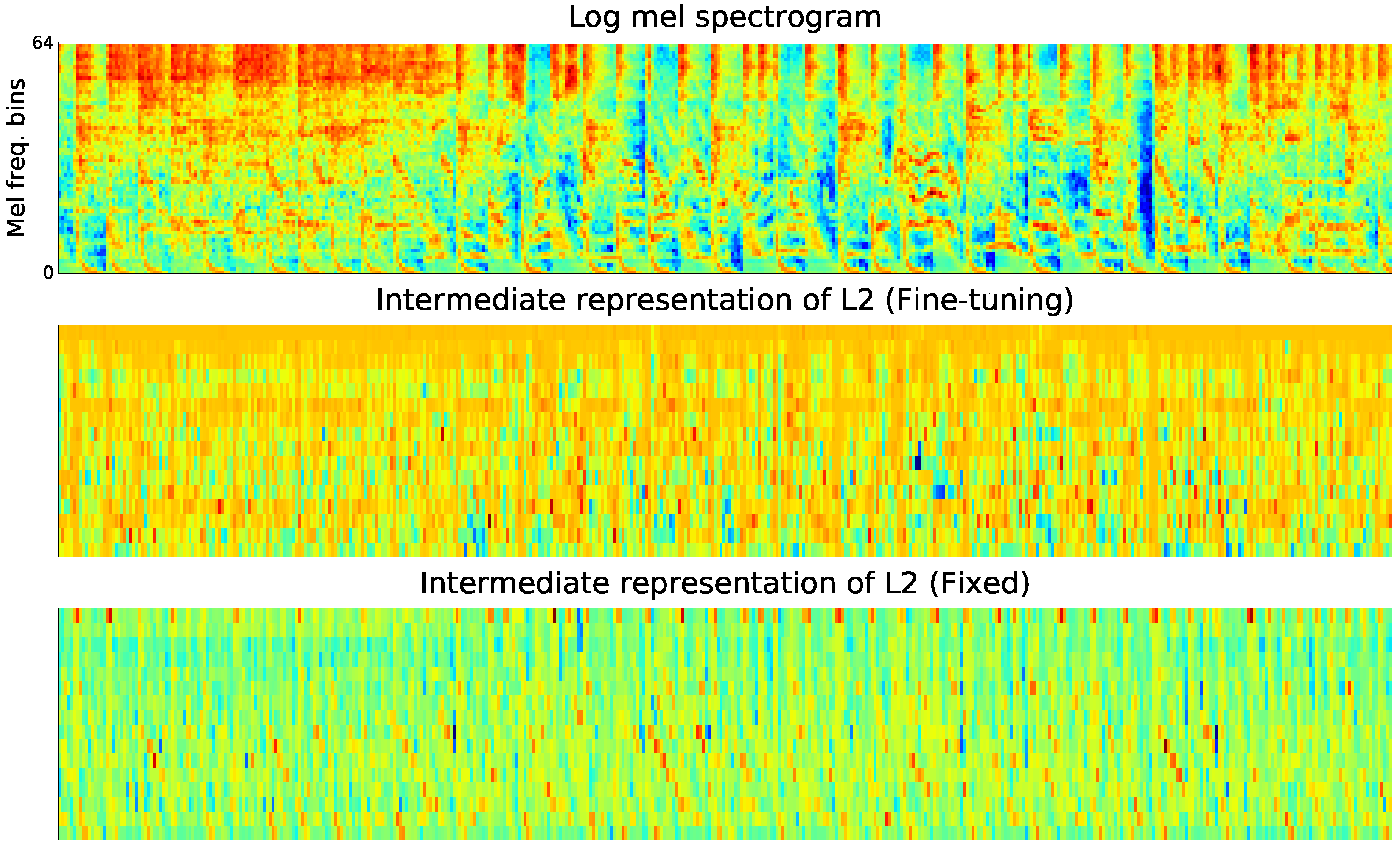
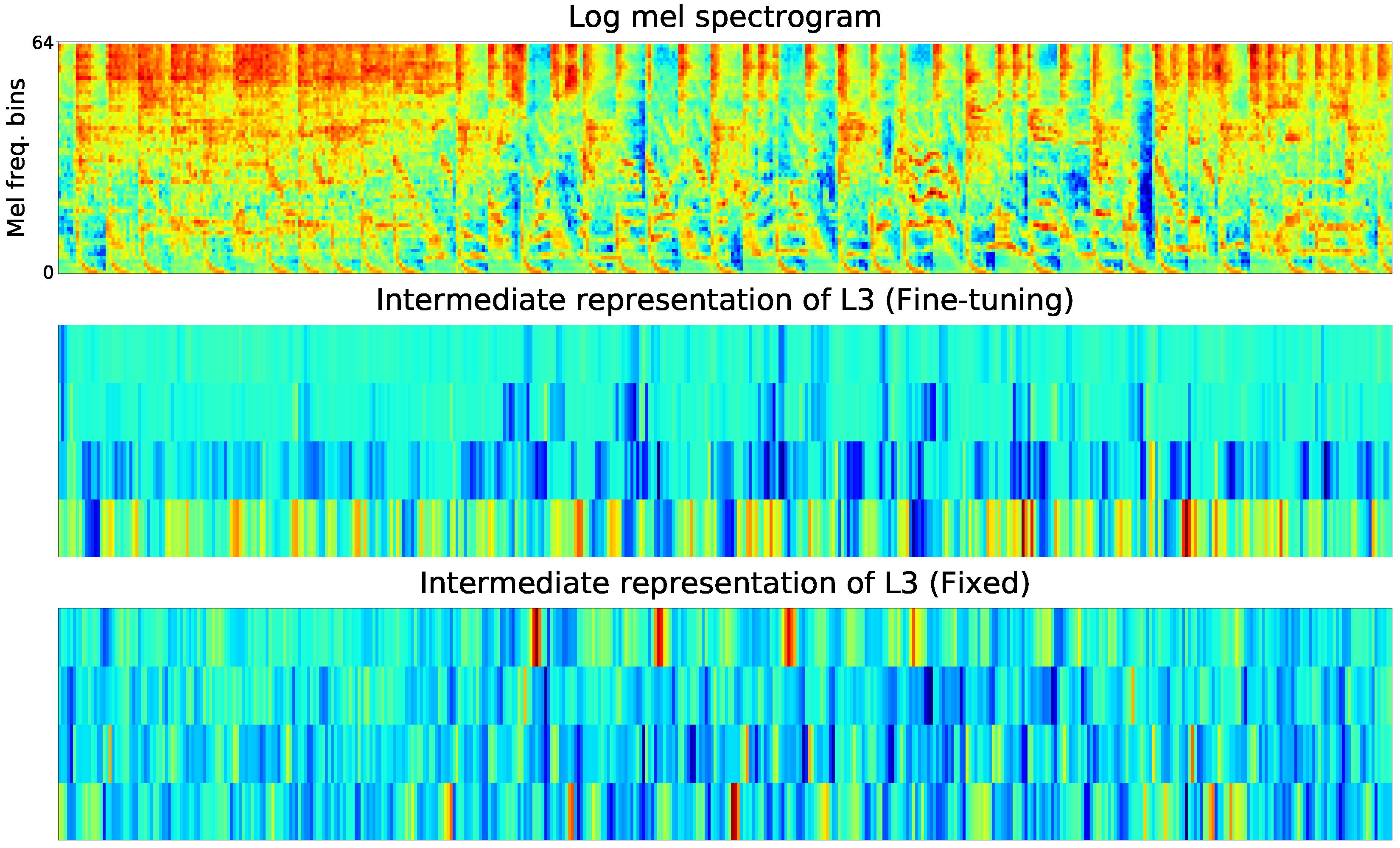
To gain deeper insights of the proposed method, we visualized the internal representations of the fixed and the fine-tuning convolutional layers based on the same song clip in the target task. From top to bottom in each graph, they are: 1) log mel spectrogram of the audio clip; 2) the output of Li in Fine-tuning mode in the target task; 3) the output of Li in Fixed mode in the target task.
Due to the limitation of space, the internal representations of one feature map, which was randomly selected from the feature maps, In these Figures, L1 learns more obvious basic local features of the input spectrogram than L2 and L3. The L1 after fine-tuning, whose representations of high frequency harmonics are abundant, learns more high frequency harmonic components than that of fixed one. The fine-tuned and retrained L1 preserves features of the input audio clip better and matches the target domain more closely
For more samples about the internal representations learned in the target task, please visit here
: https://github.com/moses1994/singing-voice-detection/tree/master/4-internal-representations-of-feature-maps
In these videos, the middle black vertical line represents the current playback position, the blue lines indicate the raw audio waves, the yellow block represents the singing voice activity, and the gray block indicates the non-singing area.
Song 1: Gaosuwo
Song 2: Haoxianghaoxiang
Song 3: Duolaimi
Song 4: Mote
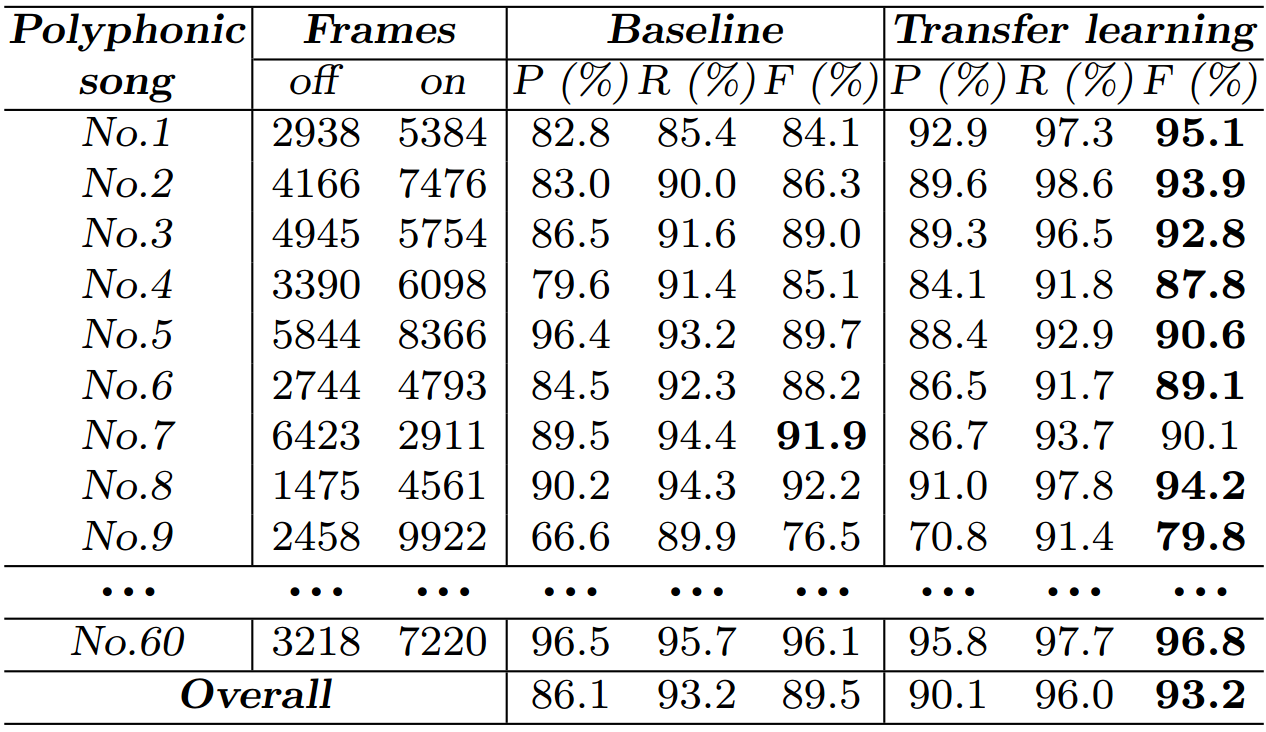
It is noteworthy that after transfer learning, the CRNN model in the target task detected the “thanks” voice of the singer to the audience at the concert, at 4:39 seconds of the fourth song named “Mote.wav”. However, the baseline system trained in the target task did not detect it. This may be due to the speech data in the source task has voice samples related to "thank you", and after transfer learning, the CRNN model in the target task absorbed these knowledge.